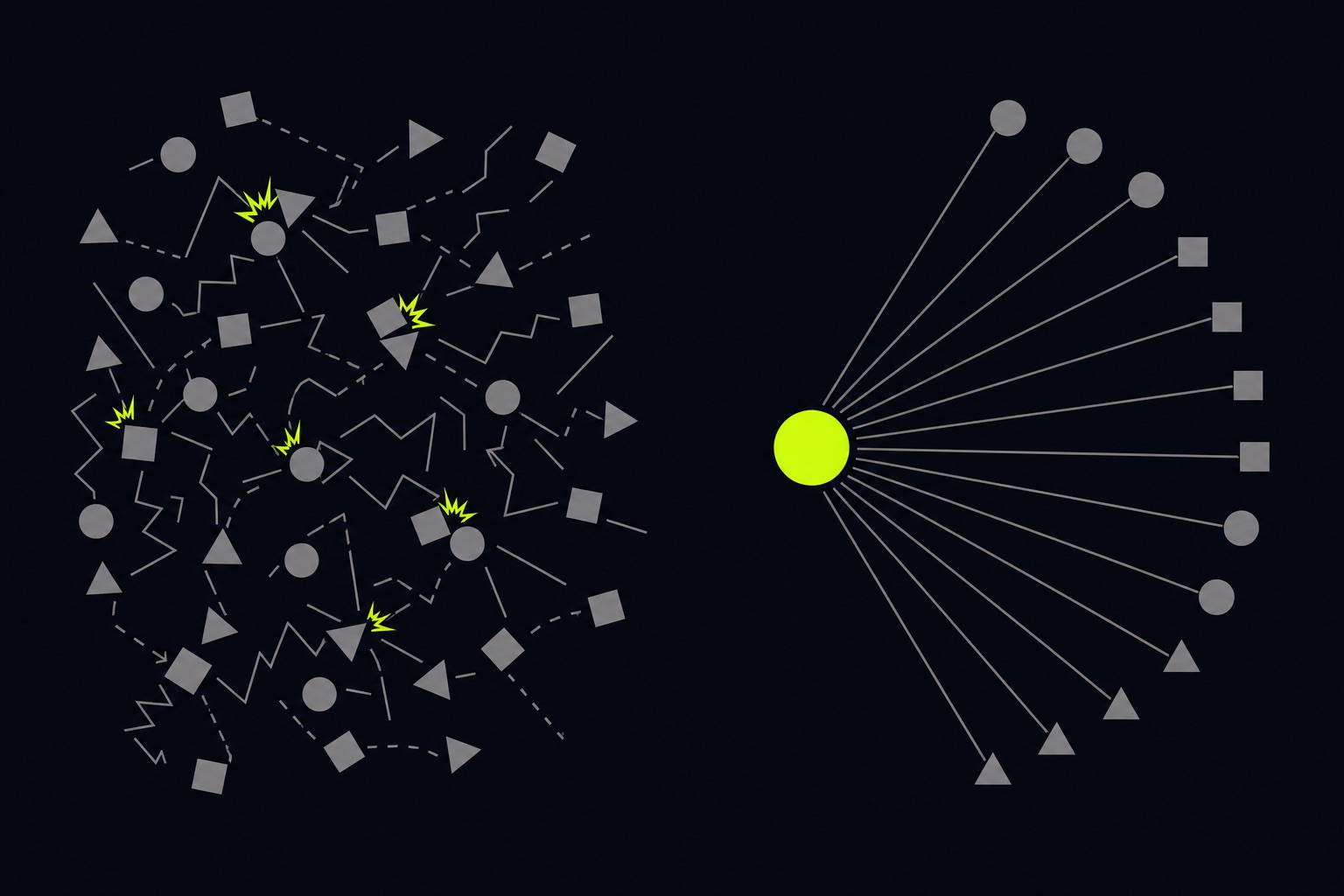
Your multi-agent system isn't failing on the model. Berkeley counted where.
When a multi-agent setup underperforms, the reflex is a bigger model or more agents. A UC Berkeley team read 1,600 failed traces across seven frameworks and found that three quarters of the failures were specification and coordination, not the model. The work is the orchestration.
tsukumo
Short version: when a multi-agent setup underperforms, almost everyone reaches for the same two fixes: a bigger model, or more agents. A team at UC Berkeley did something more useful. They sat down and read 1,600 failed runs across seven different multi-agent frameworks, one trace at a time, and labelled exactly where each one went wrong. The answer is not flattering to the bigger-model instinct. Three quarters of the failures happened before verification even ran, in the parts you build, not the part you call.
The paper is "Why Do Multi-Agent LLM Systems Fail?" (Cemri, Pan, Yang et al., UC Berkeley, 2025). The output is MAST, the first failure taxonomy for multi-agent LLM systems. The method matters here, because it's the opposite of a vibe: six expert annotators hand-read execution traces from seven popular frameworks, reached strong agreement on what broke (Cohen's kappa of 0.88), and sorted every failure into 14 named modes under three headings.
The split across the corpus:
System design and specification: 43.9%. The agents were pointed at the wrong problem, or given instructions loose enough to interpret three ways.
Inter-agent misalignment: 32.2%. The agents had the right task and talked past each other: ignored a peer's output, dropped a handoff, drifted from the plan.
Task verification: 23.9%. The work was wrong and nothing caught it before it counted.
Add the first two and you get 76% of failures landing in design and coordination, before a single output is even checked. None of those three buckets is "the model wasn't smart enough." They're all properties of the system around the model.
The instinct is understandable. The model is the part you can swap in an afternoon, so it's the part you blame. But look at where the failures sit. A smarter model that's been handed an ambiguous spec will produce a more fluent, more confident answer to the wrong question. A smarter model in a system with no handoff protocol will still drop the handoff. Capability doesn't fix coordination, because coordination was never a capability problem.
The authors put a sharp edge on this. In their words, MAS failure "is not merely a function of challenges in the underlying model; a well-designed MAS can result in performance gain when using the same underlying model." Same model, better system, better result. That sentence is the whole argument, measured.
This is the exact gap an agent-ops assessment looks for: not whether your model is good enough, but whether the system around it can keep a fleet of agents pointed at the right work and honest about the output.
There's a second reflex worth killing, because it's the one that scales the damage. If one agent underperforms, add a planner. If the planner underperforms, add a critic. Each new agent feels like progress and adds two things you now have to get right: another spec to write unambiguously, and another handoff to coordinate. Both of those are MAST's top failure categories. So a fleet you grow without a coordination layer doesn't multiply throughput. It multiplies the surface where specification and misalignment failures happen, which is most of them.
We hit this directly. We run a fleet of agents to build and market our own software, and the early version was exactly this trap: more agents, more roles, and a falling completion rate. The fix wasn't fewer agents or a better model. It was building the layer underneath them, which is the unglamorous half nobody demos.
Write the task so an agent can't read it three ways. That means machine-checkable acceptance criteria, the failure being defined as precisely as the success, and the agent grounded in artifacts that can say no: types, tests, schemas. Most "the agent did something weird" stories are really "the agent did exactly what the spec allowed." We catalogue the specific shapes this takes in why AI coding agents fail.
Agents should coordinate through shared, current state, not by re-deriving context or guessing what the last agent did. That's a real system you build: a source of truth they all read and write, with freshness so the next agent reads the latest, not a stale copy. This is the entire premise of orchestrating agent fleets instead of running a pile of agents in parallel and hoping.
The one hard number we have lives here. trovex, our open-source context server, cuts roughly 60% of the tokens per lookup by serving the currently-correct slice for the task instead of dumping the repo into the window. Cheaper is the side effect. The point is that every agent reads the same current truth, which is the coordination problem MAST measured, solved at the source.
Put a gate between an agent's output and anything downstream that depends on it. Tests it can't edit its way out of, a review step (human or another agent) that has to clear, a check the work can actually fail. An agent with no verification isn't faster. It's just unsupervised.
Honesty, since this is the part the pitch usually skips: orchestration is necessary, and it is not a silver bullet. The same Berkeley team tried targeted fixes and got real but bounded gains, around 15.6% from workflow changes, with completion rates still short of solved. So two things are true at once. The operating model is where most of your failures live and where most of your improvement will come from. And for plenty of tasks, the right answer is one well-grounded agent with a tight spec, not a fleet at all. Multi-agent is a tool with a cost, not a destination. If a single agent clears the bar, the most reliable system is the one you didn't build.
We build and run our own agent fleets in production, and we run this entire growth team on a relay of coordinated agents. So MAST didn't tell us anything our completion rates hadn't already taught us the slow way. The model is the cheap, swappable part. The specification, the shared state, and the verification gate are the work, and they're the work whether you have one agent or twenty.
If your multi-agent system is underperforming and the next move on the roadmap is "try the bigger model," that's worth a second look. The evidence says the lever is somewhere else.
We read your setup for exactly these failure modes: ambiguous specs, missing shared state, no verification gate.
Scaling an agent fleet that isn't getting more reliable?
Mostly on design and coordination, not model capability. UC Berkeley's MAST study read 1,600+ failed traces and found 43.9% of failures came from system design and bad specification, 32.2% from agents miscoordinating, and 23.9% from weak verification. Agents act on wrong assumptions, talk past each other, and ship unchecked work. A stronger model makes those mistakes faster, not less often.
What is the MAST study?
MAST (Multi-Agent System Failure Taxonomy) is a 2025 UC Berkeley paper, "Why Do Multi-Agent LLM Systems Fail?", that catalogues how multi-agent systems break. The authors hand-annotated traces from seven frameworks, reached high agreement (Cohen's kappa 0.88), and grouped failures into 14 modes across three categories: system design, inter-agent misalignment, and task verification.
Does adding more agents make a system more reliable?
Not by itself, and often the reverse. Each agent you add is another set of assumptions to misalign and another handoff to drop. MAST found that the dominant failure categories are specification and coordination, both of which get harder as you add agents. More agents without a coordination layer multiplies the failure surface instead of the throughput.
How do you make a multi-agent system reliable?
Spend the effort where the failures are. Write specifications an agent can't misread, give the agents a shared source of truth so they coordinate through state instead of guesswork, and put a verification gate between the agent's output and anything that ships. MAST's authors showed the same model in a better-designed system performs measurably better.