Short version: "AI reads your documents" is the easy demo and the wrong mental model. When we replaced a legacy document-management system with a doc-intelligence platform, the model reading a page was the part that already worked. The work was the boring pipeline around it: splitting a scanned bundle into the actual documents inside it, classifying each one into 142 real business categories, and extracting the entities that matter, reliably, across an 89,000-document backlog. A chatbot over your files impresses in a meeting. Beating the humans you are replacing on splitting and classification is what ships.
Why isn't "AI reads your documents" enough?#
Because the document you hand the AI in the demo is already split, already classified, and already clean. Real ones are none of those.
The picture everyone has is an LLM reading a tidy invoice and pulling out the total. That part genuinely works now. But it assumes the upstream problems are solved: that someone already separated this invoice from the eleven other documents in the same scan, already decided it was an invoice and not a delivery note, and already produced legible text. In a real backlog, nothing upstream is done. The model is waiting on a pipeline that doesn't exist yet, and building that pipeline is the project.
The demo starts at the one place the real work has already finished. That gap, between "AI can read this page" and "AI can process this backlog," is the whole engagement.
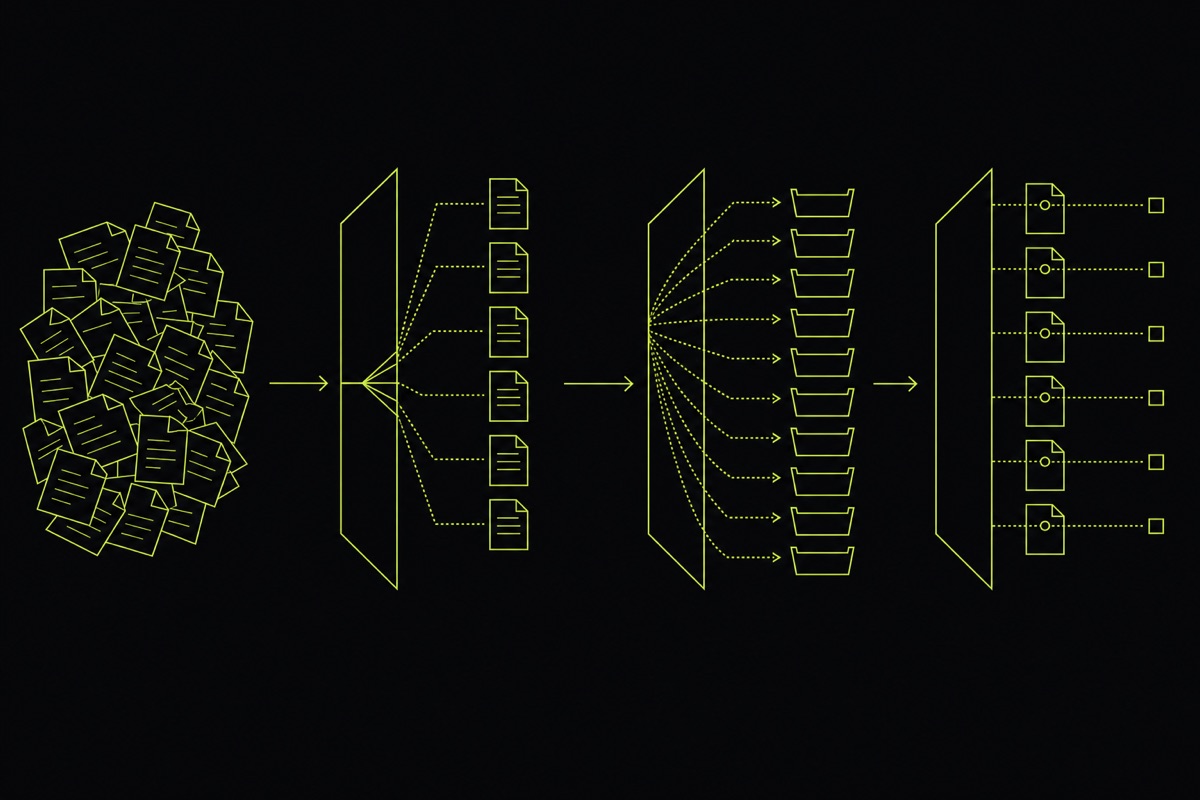
A doc-intelligence system is three stages, and they run in this order for a reason.
- Split. Turn a raw bundle (a 200-page scan, an email with attachments) into the individual documents it actually contains. Get this wrong and every later stage is operating on the wrong unit.
- Classify. Sort each document into the real category it belongs to, out of the full business taxonomy, with a confidence score.
- Extract. Pull the fields and entities that matter from each classified document.
Most teams build stage 3 first because it is the fun one, then discover the system fails on stages 1 and 2, where the documents are still bundled and unlabelled.
Splitting: the stage everyone forgets#
A scan is not a document. It is a stack, and the AI has to find the seams.
A single PDF from a scanner is routinely several distinct documents joined end to end: a contract, then a form, then three invoices, then a letter. A human flipping through finds the boundaries without thinking. An automated pipeline has to detect them, and a wrong boundary poisons everything after it, because now an invoice's second page is classified as the start of a new document. Splitting is unglamorous, it is rarely in the demo, and it is the first thing that breaks at scale.
Classifying into 142 real categories, not 5#
Demos classify into a handful of clean buckets. The business had 142, and many of them looked almost the same.
A real taxonomy is not "invoice, contract, other." It is dozens of categories with overlapping language and subtle distinctions that matter legally or operationally. A classifier trained on five labels collapses the moment it meets the real list. What works is the actual taxonomy, real labelled examples, and, critically, a confidence threshold: a document the model is unsure about goes to a human queue instead of being filed wrong with false confidence. The jump from 5 demo classes to 142 real ones is where most document-AI projects quietly stall.
Once a document is split and classified, extraction is the part that most resembles the demo, but it still has to survive bad scans.
This is where a focused entity model earns its place. We used GLiNER, an open named-entity model, for reliable extraction across document types, rather than asking a general LLM to free-form every field and hoping the format held. The point is the same one that runs through every production-AI story: use the right tool for each stage, and don't make one model carry a job a smaller, specialized one does more reliably.
Legacy DMS vs a doc-intelligence pipeline#
The old system and the new one are doing different jobs, which is exactly why "just buy a better DMS" misses the point.
A DMS is a filing cabinet that assumes a clerk. Doc-intelligence is the clerk. Replacing one with the other is not a migration, it is automating the judgement the clerk was doing.
What it takes to beat the humans you're replacing#
Automation only counts if it is more accurate than the people it replaces, not just faster.
That bar is unforgiving on an 89,000-document backlog: a 2% misclassification rate is over a thousand documents filed wrong, quietly, in a system people will trust. So the design has to know its own uncertainty and escalate, treat splitting as a first-class accuracy problem, and prove itself against a human-labelled set before it is allowed to run unattended. The win is real, but it comes from the pipeline's discipline, not from the model's cleverness.
What this means for your team#
If you are looking at an aging document system and a vendor is selling you "AI search over your files," ask what happens before the search: who splits the bundles, who classifies into your real taxonomy, what happens when the model is unsure. The model reading a page is solved. The pipeline that gets a messy backlog to that page is the engagement, and it is the part that decides whether the thing is trustworthy.
We build these where the document is the business and a misfile is a real problem. If your team is trying to retire a legacy document system with AI that actually beats the status quo, that's the work we do.
Related reading: RAG in production over regulations and client documents and GPT isn't enough: deterministic state machines over the LLM.