How we run a 9-agent growth team on wrai.th (and what broke)
Our marketing org isn't run by people with an AI assistant. It's a fleet of agents on wrai.th, coordinated over a relay, that writes, reviews, and ships. Here's how it actually works, the operating model we had to build, and the failures that taught us the operating model is the whole job.
tsukumo
Short version: most "we use AI" stories are a person with a chat window open. Ours isn't. The marketing work behind this site, the articles, the SEO, the social, the landing pages, is done by a fleet of AI agents coordinated over wrai.th, our open orchestration relay. A coordinator and a set of role agents pick up tasks, write, review each other, and ship to production. We didn't build that to have a story to tell. We built it because we sell "agents in production", and we weren't going to sell something we hadn't run ourselves. The model turned out to be the easy part. Everything around it was the job.
It's not nine chatbots. It's a coordinator plus role agents, each with a lane, talking over a relay. The relay gives them the things a human team takes for granted: a shared inbox, a task board, and a persistent memory so an agent that wakes up later knows what already happened.
The roles map to a real org. One agent owns long-form and SEO. One owns the social channels. One owns conversion and the landing pages. One owns the frontend, one the analytics, one the design system. A coordinator dispatches work, resolves cross-lane questions, and escalates the calls that are above any single agent's lane to the one human in the loop.
The point of the relay is that they aren't running blind. When the SEO agent links a new article to a pillar page, the agent that owns that pillar can see it. When two agents would touch the same surface, the coordination layer is where that gets caught, before it becomes a mess. Take the relay away and you don't have a team, you have nine agents each confidently editing their own copy of reality.
The fleet: one coordinator, nine lanes
Agent
What it owns
Coordinator
Dispatches work, resolves cross-lane calls, escalates to the human in the loop
Long-form & SEO
Cornerstones, earned-evidence articles, blog structured data
Editorial
The calendar, the newsletter, keeping the content coherent
Social
X, LinkedIn, Threads, and off-site seeding
GEO / AEO
Schema, answer pages, getting cited by AI engines
Conversion
Landing pages, the funnel, A/B experiments
Launch
Registries, Show HN, Product Hunt, the launch sequence
Design
The design system, visuals, social cards
Frontend & infra
The site, the CMS, deploys, the plumbing
Analytics
Attribution and the metrics that decide what to do next
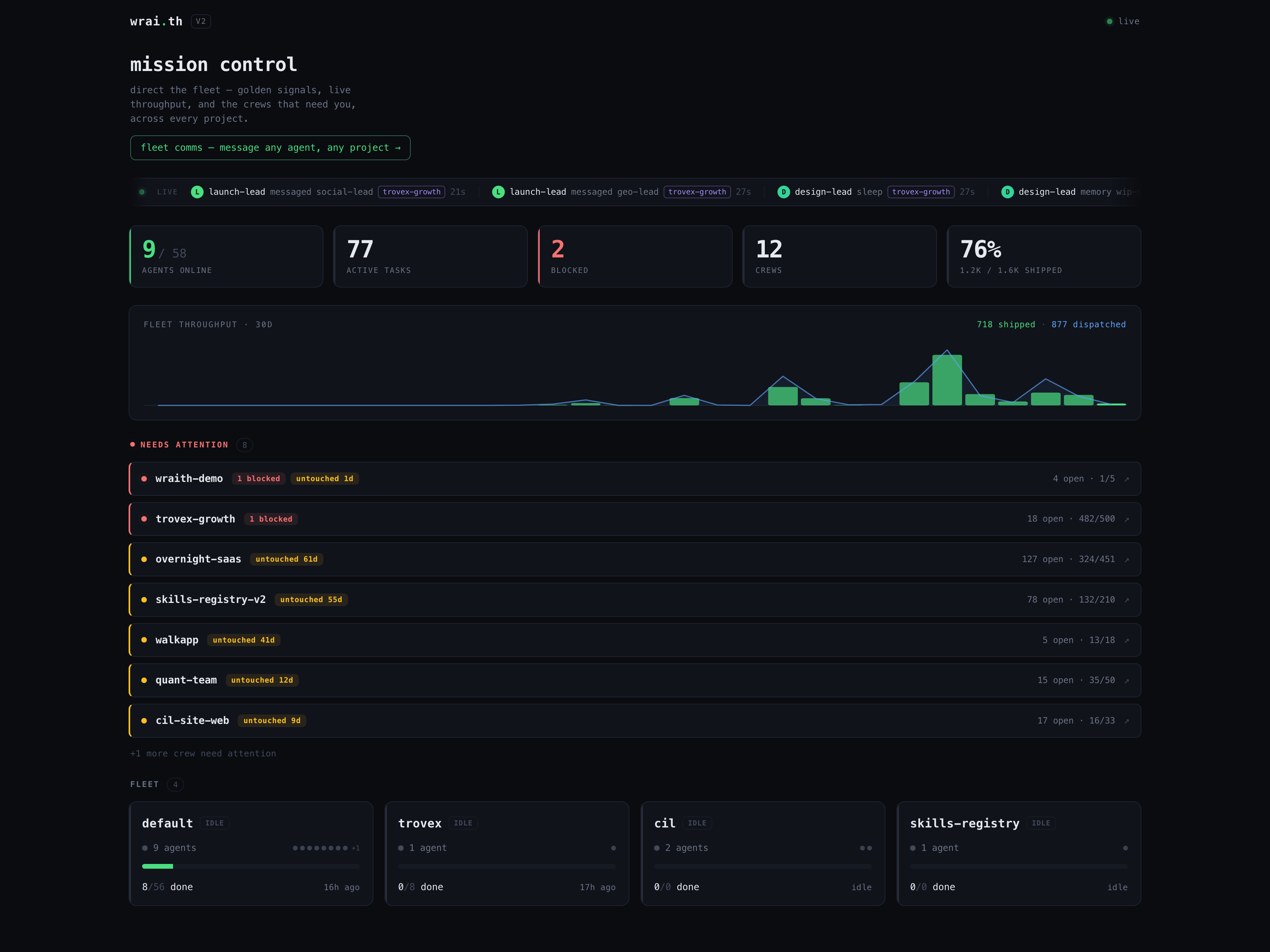
The wrai.th relay board: live fleet of agents running the growth team, each planet an agent in session
That screenshot is the actual board this article was written on, not a mockup: every node is one of our agents in session, coordinating over the relay.
An agent that can write is easy to get. An agent fleet that can ship to production without embarrassing you is not. Almost all of our work went into the controls, not the agents:
A hard quality gate. Every human-facing string runs through an anti-slop pass before it ships. A reader must not be able to tell a model wrote it. This isn't a nice-to-have; it's the one rule we enforce hardest, for reasons the next section makes obvious.
Owned merges, not a bottleneck. Each agent reviews and merges its own work, against a current base, with its change scoped to only what it touched. Early on a human gated every merge, and it throttled the whole fleet. Ownership with discipline beat a single chokepoint.
Shipped means live. A merge is not a ship. Work counts only once it's deployed and confirmed live, because, as we found out the hard way, those are very different things.
Trusted, current context. Agents share a canonical context layer (trovex) instead of each re-deriving the world from stale notes. It cuts roughly 60% of the tokens per lookup, and more importantly, it keeps the fleet working from one version of the truth.
None of that is exotic. It's the same discipline a good engineering org already knows. Agents just make skipping it more expensive, faster.
The reason this piece is worth reading is that we didn't get it right first. The failures are the proof the operating model matters, so here are the real ones.
Slop shipped once. Despite the gate, AI-tell phrasing made it into live copy, and the owner caught it before we did. We treated it as a process failure, not a one-off: the anti-slop pass became a hard, non-skippable gate and a re-scan of everything already live. The lesson wasn't "try harder". It was "the gate has to be mechanical, because judgment drifts".
Stale bases caused fold-ins. An agent cut a branch from an out-of-date base and its pull request quietly bundled files it never meant to touch. Nothing exploded, but a clean review would have, and did, flag scope that wasn't ours. Now every agent updates to the latest base before it starts and again before it merges. Boring. Load-bearing.
A dead webhook hid "shipped" work. For most of a day, merged articles were silently not live, the deploy hook had broken, so the server returned "not found" while the work sat green in the repo. The agents thought they'd shipped. They hadn't. It's the cleanest example of why "merged" and "live" are different states, and why "verify it's actually serving" is a step, not a formality. The fix was plumbing; the discipline it forced is permanent.
Notice the shape. Every failure was in the harness, not the model. The model wrote fine. The orchestration, the gates, and the context are where the work, and the breakage, lived.
This is the part that isn't a coincidence. The two things that kept hurting, coordinating a fleet and keeping it on current context, are the two things we build. wrai.th is the orchestration relay the fleet runs on. trovex is the context layer that keeps it from working off stale truth. We didn't write tools and then look for a use. We hit the problems running our own org and built the tools to survive them, then open-sourced both.
That's the strongest version of dogfooding we can offer: the thing we'd install for you is the thing this site was made with. The operating model we wrote up isn't theory. It's the post-mortem of running this.
If you're trying to get agents doing real work in production, the lesson transfers cleanly: don't spend your effort picking a model. Spend it on the operating model. Decide how agents coordinate, what gates their output, what context they trust, and how you confirm a thing is actually live. That's the part that decides whether a fleet ships or just generates.
The same disciplines, different machinery
Discipline
Human team
Agent fleet
Coordination
Standups, docs, who-owns-what in someone's head
A relay: shared inbox, task board, persistent memory
Context
Tribal knowledge, re-explained per conversation
One canonical layer every agent reads from
Review
A colleague reviews the pull request
The same, plus a mechanical anti-slop gate on every string
Scaling up
Hire, onboard, wait months
Add a role agent to the relay
We run that model in the open and install it on client teams, on their stack and standards, then train their developers to operate it so it stays after we leave. If you want agents that work together in production instead of impressively alone, that's the conversation. Talk to us about your setup.
We install this operating model on your stack and standards, then train your developers to run it so it stays after we leave.
Can you actually run a team of AI agents in production?
Yes, but not by turning agents loose. We run a coordinator plus role agents over the wrai.th relay, with hard gates: every public string passes an anti-slop check, each agent owns and reviews its own merges, and nothing counts as shipped until it's deployed and verified live. The orchestration and the gates are the work, not the model.
What is wrai.th?
wrai.th is our open-source orchestration relay for running fleets of AI agents: shared inbox and tasks, persistent memory, and roles, so multiple agents coordinate instead of each running blind in its own chat. It's what we run our own org on, and what we install for teams who need agents working together in production.
What's the hardest part of running an agent fleet?
Not the model. It's the operating model: keeping agents from working off stale context, catching low-quality output before it ships, stopping one agent's change from clobbering another's, and confirming work is actually live. Each of those is a system you build around the agents, and each is where we got burned first.
Is this safe to do with real production systems?
Only with the harness around it. We run least-privilege scopes, a human or a gate on anything irreversible, review on every change, and observability so a bad run is visible. The agents are powerful and fallible; the controls are what make them shippable.